DBS101_Unit7
UNIT 7: Database Systems Fundamentals: Transactions, Concurrency Control, and Recovery
Lesson 18: Database Transactions
What I Learned About Transactions
I learned that a transaction is a collection of operations that form a single logical unit of work in a database. It’s essentially a unit of program execution that accesses and possibly updates various data items. Transactions are delimited by begin transaction and end transaction statements.
ACID Properties - The Foundation of Transactions
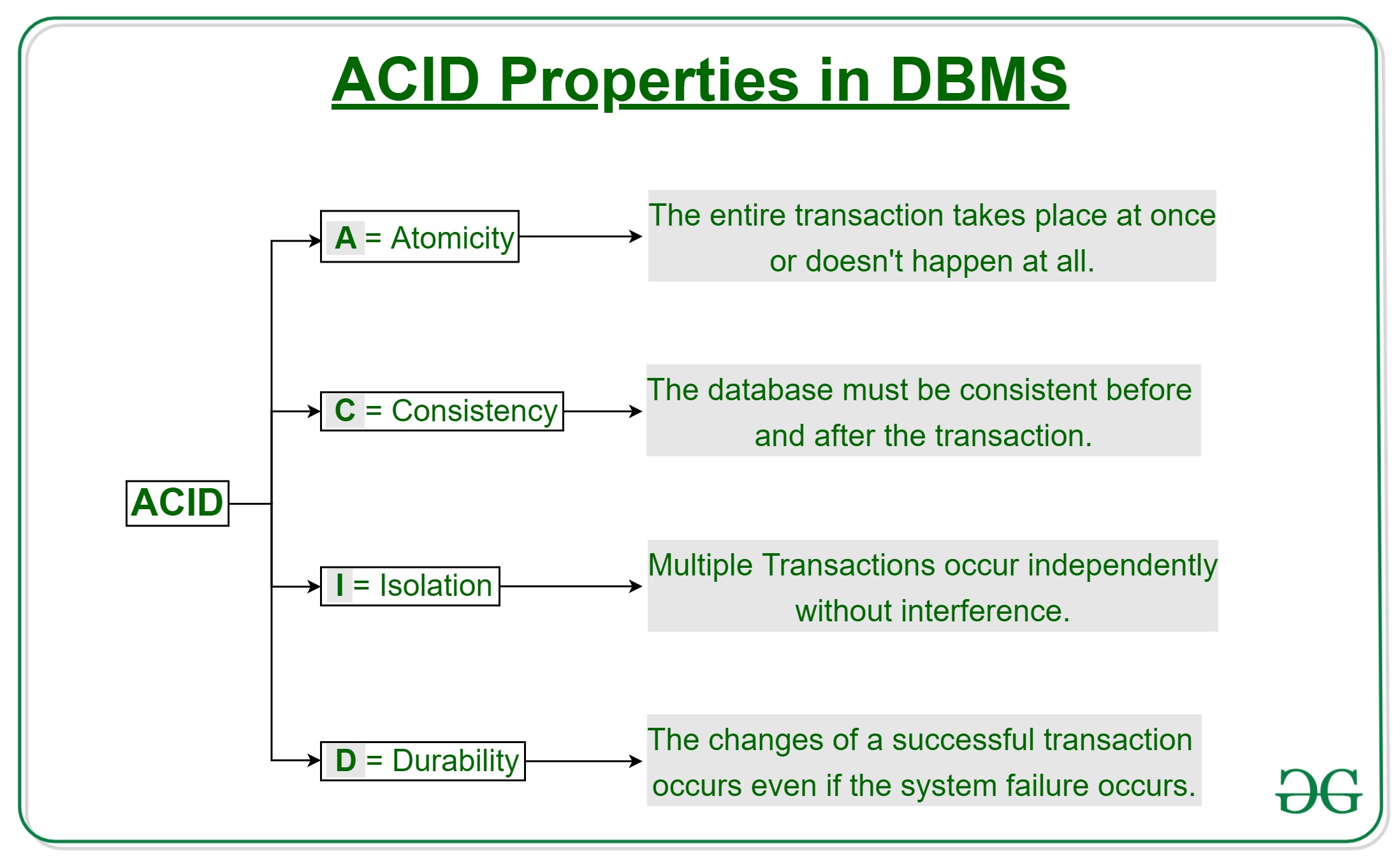
Transaction must possess four critical properties known as ACID:
- Atomicity: Either all operations of the transaction are reflected properly in the database, or none are
- Consistency: Execution of a transaction in isolation preserves the consistency of the database
- Isolation: Multiple transactions executing concurrently appear to run one after another
- Durability: After a transaction completes successfully, changes persist even if there are system failures
Simple Transaction Model Example
A practical example of transferring $50 from account A to account B:
- Initial values: A = $1000, B = $2000
- Transaction operations: read(A), A := A - 50, write(A), read(B), B := B + 50, write(B)
This example helped me understand how ACID properties work:
- Consistency: Sum of A and B remains unchanged
- Atomicity: All or none of the operations are executed
- Durability: Updates persist even after system failure
- Isolation: Concurrent execution is equivalent to serial execution
Storage Structure and Transaction Requirements
Different storage types:
- Volatile storage: Doesn’t survive system crashes (main memory, cache)
- Non-volatile storage: Survives system crashes (magnetic disk, flash storage)
- Stable storage: Information never lost (achieved by replicating data)
For transactions to be durable, changes must be written to stable storage. For atomicity, log records must be written to stable storage before any changes to the disk database.
Transaction States
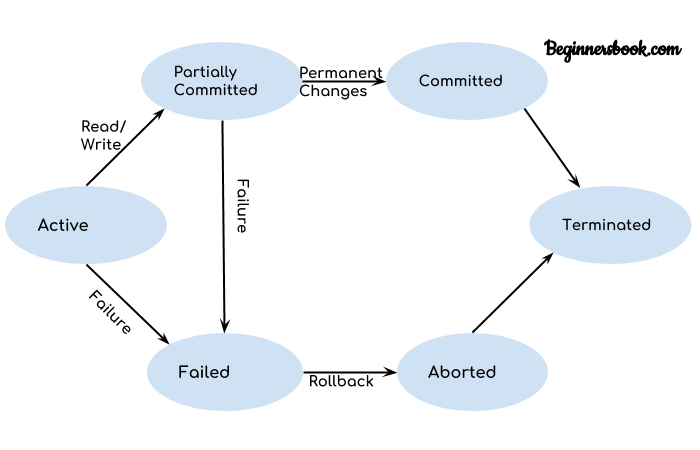
The five states a transaction can be in:
- Active: Initial state, transaction executing
- Partially committed: After final statement execution
- Failed: Abnormal execution, can’t proceed
- Aborted: Rolled back, database restored to pre-transaction state
- Committed: Successfully completed
Transaction Isolation and Scheduling
There are two types of schedules:
- Serial Schedule: Transactions executed one after another
- Non-serial Schedule: Operations of multiple transactions are interleaved
Serializability ensures that concurrent schedules are equivalent to serial schedules, maintaining database consistency.
Conflict Serializability
how to determine if schedules are conflict serializable:
- Two instructions conflict if they belong to different transactions, access the same data item, and at least one is a write operation
- Precedence graphs help test conflict serializability - if there’s no cycle, the schedule is conflict serializable
Lesson 19: Concurrency Control and Locking
Understanding Locks
I learned that locks enable transactions to acquire read or write access to data, ensuring conflict prevention and isolation enforcement. There are two main lock modes: 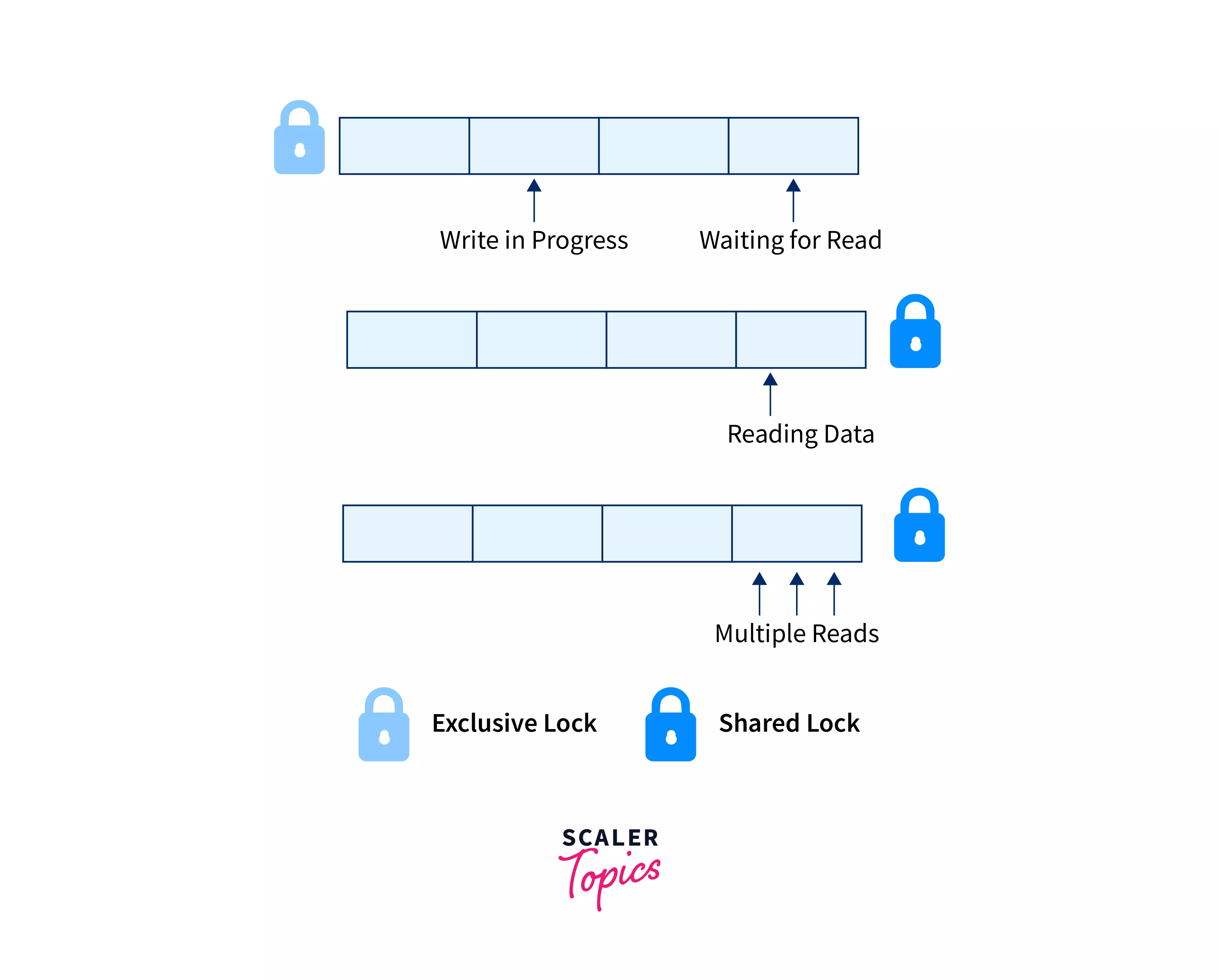
- Shared (S) locks: Allow reading but not writing
- Exclusive (X) locks: Allow both reading and writing
Two-Phase Locking Protocol
The two-phase locking protocol that ensures serializability:
- Growing phase: Transaction may obtain locks but not release any
- Shrinking phase: Transaction may release locks but not obtain new ones
Deadlock Management
Two approaches to handle deadlocks:
Deadlock Detection:
- Uses waits-for graphs to detect cycles
- Selects victim transactions to rollback based on age, progress, or number of items locked
Deadlock Prevention:
- Wait-Die: Older transactions wait for younger ones, younger ones abort
- Wound-Wait: Older transactions force younger ones to abort
Lock Granularities and Intention Locks
Different levels of locking:
- Intention-Shared (IS): Intent to get S locks at finer granularity
- Intention-Exclusive (IX): Intent to get X locks at finer granularity
- Shared+Intention-Exclusive (SIX): Subtree locked in S mode with X locks at lower levels
Concurrency Control Approaches
Different approaches to concurrency:
Pessimistic: Assume conflicts will occur (Two-Phase Locking, Timestamp Ordering) Optimistic: Assume conflicts are rare, check after execution
Timestamp Ordering
How timestamps determine serializability order:
- If TS(Ti) < TS(Tj), then Ti must appear before Tj in execution
- Thomas Write Rule allows ignoring certain writes to avoid unnecessary aborts
Multi-Version Concurrency Control (MVCC)
MVCC maintains multiple physical versions of objects:
- Writers don’t block readers
- Readers don’t block writers
- Uses timestamps to determine visibility
- Supports Snapshot Isolation where transactions see consistent snapshots
Lesson 20: Recovery Systems
Importance of Recovery Systems
Why recovery systems are crucial for handling:
- System failures
- Transaction failures
- Human errors
- Hardware issues
- Natural disasters
- Data corruption
Log-Based Recovery
log records are the foundation of recovery, containing:
- Transaction identifier (Ti)
- Data item (Xj)
- Old value (V1)
- New value (V2)
Other log record types include:
<Ti start>: Transaction begins<Ti commit>: Transaction commits<Ti abort>: Transaction aborts
Database Modification Techniques
Two approaches:
- Deferred-modification: No database changes until commit
- Immediate-modification: Database changes while transaction is active
Undo and Redo Operations
Undo(Ti): Restores all data items updated by Ti to their old values Redo(Ti): Sets all data items updated by Ti to their new values
Checkpoints
checkpoints periodically record database state to:
- Limit log examination during recovery
- Allow log truncation
- Reduce recovery time
Fuzzy checkpoints allow transactions to continue during checkpointing.
ARIES Recovery Algorithm
The three-pass recovery process:
- Analysis pass: Determines which transactions to undo and dirty pages
- Redo pass: Repeats history to restore pre-crash state
- Undo pass: Rollback incomplete transactions
High Availability Techniques
I learned about:
- Remote backup systems that maintain replicas
- Hot-spare configurations for quick failover
- Distributed databases with data replication
Main-Memory Database Recovery
Special considerations for main-memory databases:
- No redo logging needed for indices
- Only undo logs kept in memory
- Parallel recovery across CPU cores
- Fast recovery critical since entire database loads into memory
Key Takeaways
Through these lessons, I gained comprehensive understanding of:
- How transactions ensure database consistency through ACID properties
- Various concurrency control mechanisms and their trade-offs
- The critical role of recovery systems in maintaining data integrity
- Practical implementation techniques used in modern database systems
The progression from basic transaction concepts to advanced recovery algorithms gave me a solid foundation in database system reliability and performance optimization.